Leçon 2
- Compilation
- Débogage
- help50 et printf
- debug50
- check50 et style50
- Types de données
- Mémoire
- Tableaux
- Chaînes
- Arguments de ligne de commande
- Lisibilité
- Cryptage
Compilation
- La dernière fois, nous avons appris à écrire notre premier programme en C. Nous avons appris la syntaxe de la fonction
maindans notre programme, la fonctionprintfpour imprimer dans un terminal, comment créer des chaînes avec des guillemets doubles et comment inclurestdio.hpour la fonctionprintf. - Ensuite, nous l'avons compilé avec
clang hello.cpour pouvoir exécuter./a.out(le nom par défaut), puisclang -o hello hello.c(en transmettant un argument de ligne de commande pour le nom de la sortie) pour pouvoir exécuter./hello. - Si nous avons voulu utiliser la bibliothèque de CS50, via
#include <cs50.h>, pour les chaînes et la fonctionget_string, nous avons également dû ajouter un indicateur :clang -o hello hello.c -lcs50. L'indicateur-lrelie le fichiercs50, qui est déjà installé dans le bac à sable CS50 et comprend des prototypes ou des définitions de chaînes et deget_string(entre autres) auxquels notre programme peut ensuite se référer et les utiliser. - Nous écrivons notre code source en C, mais nous devons le compiler en code machine, en binaire, avant que nos ordinateurs puissent l'exécuter.
clangest le compilateur etmakeest un utilitaire qui nous aide à exécuterclangsans avoir à indiquer toutes les options manuellement.
- La « compilation » du code source en code machine est en réalité constituée d'étapes plus petites :
- Prétraitement
- Compilation
- Assemblage
- Liaison
- Le prétraitement implique l'examen des lignes qui commencent par un
#, comme#include, avant tout autre chose. Par exemple,#include <cs50.h>indiquera àclangde rechercher d'abord ce fichier d'en-tête, car il contient le contenu que nous souhaitons inclure dans notre programme. Ensuite,clangremplacera essentiellement le contenu de ces fichiers d'en-tête dans notre programme. -
Par exemple …
#include <cs50.h> #include <stdio.h> int main(void) { string name = get_string("Name: "); printf("hello, %s\n", name); } -
… sera prétraité en :
string get_string(string prompt); int printf(const char *format, ...); int main(void) { string name = get_string("Name: "); printf("hello, %s\n", name); } -
La compilation prend notre code source, en C, et le convertit en code assembleur, qui ressemble à ceci :
... main: # @main .cfi_startproc # BB#0: pushq %rbp .Ltmp0: .cfi_def_cfa_offset 16 .Ltmp1: .cfi_offset %rbp, -16 movq %rsp, %rbp .Ltmp2: .cfi_def_cfa_register %rbp subq $16, %rsp xorl %eax, %eax movl %eax, %edi movabsq $.L.str, %rsi movb $0, %al callq get_string movabsq $.L.str.1, %rdi movq %rax, -8(%rbp) movq -8(%rbp), %rsi movb $0, %al callq printf ...- Ces instructions sont de plus bas niveau et se rapprochent des instructions binaires qu'un processeur d'ordinateur peut directement comprendre. Elles fonctionnent généralement sur des octets eux-mêmes, par opposition à des abstractions comme les noms de variables.
-
L'étape suivante consiste à prendre le code assembleur et à le traduire en instructions binaires en l'assemblant. Les instructions en binaire sont appelées code machine, qu'un processeur d'ordinateur peut exécuter directement.
- La dernière étape est la liaison, où le contenu des bibliothèques précédemment compilées que nous souhaitons lier, comme
cs50.c, sont réellement combinées avec le binaire de notre programme. Nous nous retrouvons donc avec un fichier binaire,a.outouhello, qui est la version compilée dehello.c,cs50.cetprintf.c.
Débogage
- Les bogues sont des erreurs involontaires qui surviennent dans les programmes. Le débogage est le processus de recherche et de correction de ces bogues.
help50 et printf
-
Supposons que nous ayons écrit ce programme,
buggy0.c:int main(void) { printf("hello, world\n"); }- Lorsque nous essayons de
makece programme, nous voyons une erreur (en rouge) indiquant que nous déclarons implicitement la fonction de bibliothèqueprintf. Nous ne comprenons pas vraiment cette erreur. Nous pouvons donc exécuterhelp50 make buggy0. Cela nous indiquera en fin de compte que nous avons peut-être oublié d’écrire#include <stdio.h>, qui contientprintf.
- Lorsque nous essayons de
-
Nous pouvons réessayer avec
buggy1.c:#include <stdio.h> int main(void) { string name = get_string("What's your name?\n"); printf("hello, %s\n", name); }- De nombreuses erreurs s’affichent, et même la première ne semble pas avoir beaucoup de sens. Nous pouvons donc à nouveau exécuter
help50 make buggy1. Cela nous indiquera que nous avons besoin decs50.hcarstringn’est pas défini.
- De nombreuses erreurs s’affichent, et même la première ne semble pas avoir beaucoup de sens. Nous pouvons donc à nouveau exécuter
-
Pour effacer la fenêtre du terminal (afin de ne voir que la sortie de ce que nous voulons exécuter ensuite), nous pouvons appuyer sur
control + Lou taperclearcomme commande dans la fenêtre du terminal. -
Examinons
buggy2.c:#include <stdio.h> int main(void) { for (int i = 0; i <= 10; i++) { printf("#\n"); } }-
Hmm, nous avions l’intention de ne voir que 10
#, mais il y en a 11. Si nous ne savions pas quel était le problème (car notre programme se compile sans aucune erreur, et nous avons maintenant une erreur logique), nous pourrions ajouter une autre ligne d’impression pour nous aider :#include <stdio.h> int main(void) { for (int i = 0; i <= 10; i++) { printf("i est maintenant %i : ", i); printf("#\n"); } } -
Maintenant, nous voyons que
ia commencé à 0 et a continué jusqu’à 10, mais nous devrions l’arrêter lorsqu’il est à 10, aveci < 10au lieu dei <= 10.
-
debug50
- Aujourd'hui, nous allons également jeter un œil à CS50 IDE, qui est comme le bac à sable de CS50, mais avec plus de fonctionnalités. C'est un environnement de développement en ligne, avec un éditeur de code et une fenêtre de terminal, mais aussi des outils pour le débogage et la collaboration :
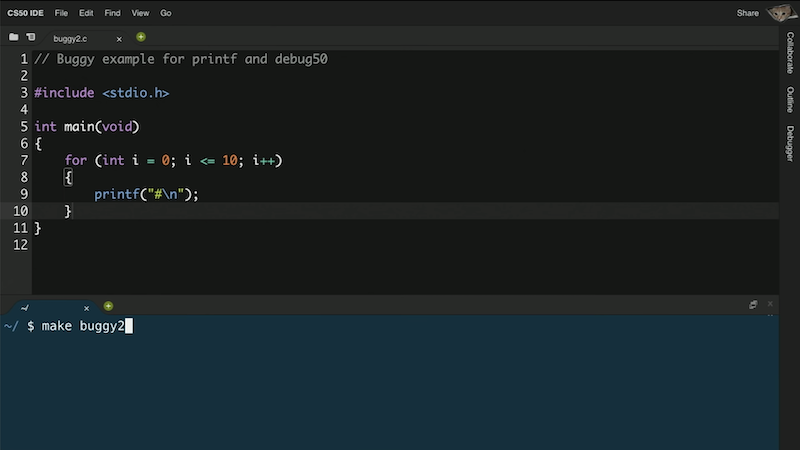
- Dans CS50 IDE, nous aurons un autre outil,
debug50, pour nous aider à déboguer les programmes. - Nous allons ouvrir
buggy2.cet essayer defaire buggy2. Mais nous avons enregistrébuggy2.cdans un dossier appelésrc2, nous devons donc exécutercd src2pour changer notre répertoire vers le bon. Le terminal de CS50 IDE nous rappellera dans quel répertoire nous sommes, avec une invite comme~/src/ $. (Le~indique le répertoire par défaut, ou le répertoire home.) - Au lieu d'utiliser
printf, nous pouvons également déboguer notre programme de manière interactive. Nous pouvons ajouter un point d'arrêt, ou un indicateur pour une ligne de code où le débogueur doit interrompre notre programme. Par exemple, on peut cliquer à gauche de la ligne 5 de notre code, un cercle rouge apparaîtra :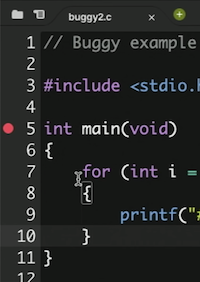
- Maintenant, si on exécute
debug50 ./buggy2, on verra le panneau de débogage s'ouvrir à droite :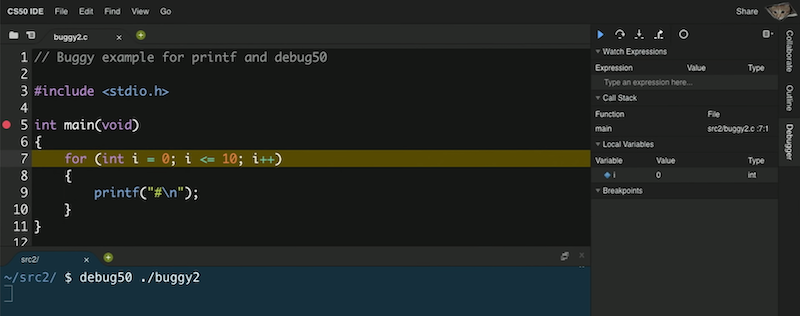
- On voit que la variable que nous avons créée,
i, est dans la sectionVariables locales, et qu'elle a une valeur de0. - Notre point d'arrêt a interrompu notre programme après la ligne 5, juste avant la ligne 7, car c'est la première ligne de code qui peut être exécutée. Pour continuer, nous avons quelques commandes dans le panneau du débogueur. Le triangle bleu continuera notre programme jusqu'à ce que nous atteignions un autre point d'arrêt ou la fin de notre programme. La flèche courbe à sa droite va « passer outre » la ligne, l'exécuter et interrompre notre programme juste après.
- Nous utiliserons donc la flèche courbe pour exécuter la ligne suivante et voir ce qui change après. Nous sommes à la ligne
printf, et en appuyant à nouveau sur la flèche courbe, nous voyons un seul#imprimé dans notre fenêtre de terminal. Avec un autre clic sur la flèche, nous voyons la valeur deisur la droite changer à1. Et nous pouvons continuer à cliquer sur la flèche pour regarder notre programme s'exécuter, une ligne à la fois. - Pour quitter le débogueur, on peut appuyer sur
ctrl + Cpour arrêter le programme. - Nous pouvons gagner beaucoup de temps à l'avenir en investissant un peu maintenant pour apprendre à utiliser
debug50!
check50 et style50
- Nous pouvons exécuter une commande comme
check50 cs50/problems/hello, oùcheck50est un programme qui suivra les instructions identifiées par l'argumentcs50/problems/hellopour télécharger, exécuter et tester notre programme sur les serveurs de CS50. Cela vérifiera l'exactitude de notre programme.- Lors de l'écriture de logiciels dans le monde réel, les développeurs écrivent généralement leurs propres tests pour s'assurer que leur code fonctionne comme prévu, d'autant plus que des fonctionnalités sont ajoutées au même code.
style50est un autre programme qui vérifiera notre code pour des problèmes esthétiques, comme les espaces, de sorte que notre code soit plus lisible et maintenable. Par exemple, il se peut que notre indentation soit manquante. Et le guide de style inclura davantage d'explications sur ce que nous attendons.- Nous pouvons même utiliser le débogage du canard en caoutchouc, une méthode où nous expliquons ce que nous essayons de faire à un canard en caoutchouc, de sorte que nous réalisions ce que nous essayons de faire et ce que nous devons corriger.
- Nous voulons également écrire notre code avec une bonne conception, où nous résolvons non seulement le problème correctement, mais aussi bien, où nous faisons des choix raisonnables quant à la façon dont notre programme s'exécute et faisons des compromis entre le temps, le coût de développement et la mémoire.
Types de données
- En C, nous avons différents types de variables que nous pouvons utiliser pour stocker des données :
- bool 1 octet
- char 1 octet
- int 4 octets
- float 4 octets
- long 8 octets
- double 8 octets
- string ? octets
- Chacun de ces types occupe un certain nombre d'octets par variable que nous créons, et les tailles ci-dessus sont celles que le bac à sable, l'IDE et très probablement votre ordinateur utilisent pour chaque type en C.
Mémoire
- À l'intérieur de nos ordinateurs, nous avons des puces appelées RAM, mémoire à accès aléatoire, qui stockent des données pour une utilisation à court terme. Nous pourrions enregistrer un programme ou un fichier sur notre disque dur (ou notre disque SSD) pour un stockage à long terme, mais lorsque nous l'ouvrons, il est d'abord copié dans la RAM. Bien que la RAM soit beaucoup plus petite et temporaire (jusqu'à ce que l'alimentation soit coupée), elle est beaucoup plus rapide.
- On peut penser aux octets stockés dans la RAM comme s'ils étaient dans une grille :

- En réalité, il y a des millions ou des milliards d'octets par puce.
- En C, lorsque nous créons une variable de type
char, qui sera de taille un octet, elle sera physiquement stockée dans l'une de ces cases de la RAM. Un entier, avec 4 octets, prendra quatre de ces cases. - Et chacune de ces cases est étiquetée avec un numéro, ou une adresse, de 0 à 1, à 2, etc.
Tableaux
-
Disons que nous voulions stocker trois variables :
#include <stdio.h> int main(void) { char c1 = 'H'; char c2 = 'I'; char c3 = '!'; printf("%c %c %c\n", c1, c2, c3); }- Notez que nous utilisons des guillemets simples pour indiquer un caractère littéral, et des guillemets doubles pour plusieurs caractères ensemble dans une chaîne.
- Nous pouvons compiler et exécuter ceci, pour voir
H I !.
-
Et nous savons que les caractères ne sont que des nombres, donc si nous changeons le formatage de notre chaîne pour être
printf("%i %i %i\n", c1, c2, c3);, nous pouvons voir les valeurs numériques de chaque caractère imprimé :72 73 33.- Nous pouvons convertir explicitement, ou caster, chaque caractère en un int avant de l’utiliser, avec
(int) c1, mais notre compilateur peut le faire implicitement pour nous.
- Nous pouvons convertir explicitement, ou caster, chaque caractère en un int avant de l’utiliser, avec
- Et en mémoire, on peut avoir trois cases, étiquetées « c1 », « c2 » et « c3 » d’une certaine manière, chacune représentant un octet binaire avec les valeurs de chaque variable.
-
Regardons
scores0.c:#include <cs50.h> #include <stdio.h> int main(void) { // Scores int score1 = 72; int score2 = 73; int score3 = 33; // Print average printf("Average: %i\n", (score1 + score2 + score3) / 3); }- Nous pouvons imprimer la moyenne de trois nombres, mais maintenant nous devons créer une variable pour chaque score que nous voulons inclure, et nous ne pouvons pas les utiliser facilement plus tard.
-
Il s’avère qu’en mémoire, nous pouvons stocker des variables les unes après les autres, dos à dos. Et en C, une liste de variables stockées, les unes après les autres dans un bloc contigu de mémoire, est appelée un tableau.
- Par exemple, nous pouvons utiliser
int scores[3];pour déclarer un tableau de 3 entiers. -
Et nous pouvons assigner et utiliser des variables dans un tableau avec :
#include <cs50.h> #include <stdio.h> int main(void) { // Scores int scores[3]; scores[0] = 72; scores[1] = 73; scores[2] = 33; // Print average printf("Average: %i\n", (scores[0] + scores[1] + scores[2]) / 3); }- Notez que les tableaux sont indexés à zéro, ce qui signifie que le premier élément, ou valeur, a l’index 0.
-
Et nous avons répété la valeur 3, représentant la longueur de notre tableau, à deux endroits différents. Nous pouvons donc utiliser une constante, ou une valeur fixe, pour indiquer qu’elle doit toujours être la même aux deux endroits :
#include <cs50.h> #include <stdio.h> const int N = 3; int main(void) { // Scores int scores[N]; scores[0] = 72; scores[1] = 73; scores[2] = 33; // Print average printf("Average: %i\n", (scores[0] + scores[1] + scores[2]) / N); }- Nous pouvons utiliser le mot-clé
constpour dire au compilateur que la valeur deNne doit jamais être modifiée par notre programme. Et par convention, nous placerons notre déclaration de variable en dehors de la fonctionmainet mettrons son nom en majuscule, ce qui n’est pas nécessaire pour le compilateur, mais qui montre aux autres humains que cette variable est une constante et la rend facile à voir depuis le début.
- Nous pouvons utiliser le mot-clé
-
Avec un tableau, nous pouvons collecter nos scores dans une boucle, et y accéder plus tard dans une boucle également :
#include <cs50.h> #include <stdio.h> float average(int length, int array[]); int main(void) { // Get number of scores int n = get_int("Scores: "); // Get scores int scores[n]; for (int i = 0; i < n; i++) { scores[i] = get_int("Score %i: ", i + 1); } // Print average printf("Average: %.1f\n", average(n, scores)); } float average(int length, int array[]) { int sum = 0; for (int i = 0; i < length; i++) { sum += array[i]; } return (float) sum / (float) length; }- Tout d’abord, nous demandons à l’utilisateur le nombre de scores qu’il a, créons un tableau avec suffisamment d’entiers pour le nombre de scores qu’il a, et utilisons une boucle pour collecter tous les scores.
- Ensuite, nous écrivons une fonction d’assistance,
average, pour renvoyer unfloatou une valeur décimale. Nous passerons la longueur et un tableau deint(qui peut être de n’importe quelle taille), et utiliserons une autre boucle dans notre fonction d’assistance pour additionner les valeurs dans une somme. Nous utilisons(float)pour caster à la foissumetlengthen floats, donc le résultat que nous obtenons en divisant les deux est aussi un float. - Enfin, lorsque nous imprimons le résultat obtenu, nous utilisons
%.1fpour n’afficher qu’une décimale.
-
En mémoire, notre tableau est maintenant stocké comme ceci, où chaque valeur occupe non pas un mais quatre octets :

Strings
- Les strings sont en fait simplement des tableaux de caractères. Si nous avons une string
s, chaque caractère peut être accédé avecs[0],s[1], et ainsi de suite. - Et il s'avère qu'une string se termine par un caractère spécial, ‘\0’, ou un octet avec tous les bits à 0. Ce caractère est appelé caractère nul, ou caractère terminateur nul. Nous avons donc en réalité besoin de quatre octets pour stocker notre string "HI!" :
![Grille avec H étiqueté s[0], I étiqueté s[1], ! étiqueté s[2], \0 étiqueté s[3], chacun prenant une case et de nombreuses autres cases vides sont à la suite](https://cs50.harvard.edu/x/2020/notes/2/memory_with_string.png)
-
Voyons maintenant à quoi peuvent ressembler quatre strings dans un tableau :
string noms[4] ; noms[0] = "EMMA" ; noms[1] = "RODRIGO" ; noms[2] = "BRIAN" ; noms[3] = "DAVID" ; printf("%s\n", noms[0]) ; printf("%c%c%c%c\n", noms[0][0], noms[0][1], noms[0][2], noms[0][3]) ;- Nous pouvons imprimer la première valeur de
nomssous forme de string ou récupérer la première string et obtenir chaque caractère individuel dans cette string en utilisant[]à nouveau. (Nous pouvons considérer cela comme(noms[0])[0], bien que nous n’en ayons pas besoin les parenthèses.) - Et bien que nous sachions que le prénom avait quatre caractères,
printfa probablement utilisé une boucle pour regarder chaque caractère de la string, les imprimant un à la fois jusqu'à atteindre le caractère nul qui marque la fin de la string. Et en fait, nous pouvons imprimernoms[0][4]sous forme d’intavec%i, et voir un0s’afficher.
- Nous pouvons imprimer la première valeur de
-
Nous pouvons visualiser chaque caractère avec sa propre étiquette en mémoire :
![Grille avec E étiqueté noms[0][0], M étiqueté noms[0][1], etc. jusqu'à noms[3][5] avec un \0, chacun prenant une case et des cases vides suivent](https://cs50.harvard.edu/x/2020/notes/2/memory_with_string_array.png)
-
Nous pouvons essayer d'expérimenter avec
string0.c:#include <cs50.h> #include <stdio.h> #include <string.h> int main(void) { string s = get_string("Entrée : "); printf("Sortie : "); for (int i = 0; i < strlen(s); i++) { printf("%c", s[i]); } printf("\n"); }- Nous pouvons utiliser la condition
s[i] != '\0', où nous pouvons vérifier le caractère actuel et l’imprimer uniquement s’il ne s’agit pas du caractère nul. - Nous pouvons également utiliser la longueur de la string, mais nous avons d’abord besoin d’une nouvelle bibliothèque,
string.h, pourstrlen, qui nous indique la longueur d’une string.
- Nous pouvons utiliser la condition
-
Nous pouvons améliorer la conception de notre programme.
string0était un peu inefficace, car nous vérifions la longueur de la string, après que chaque caractère est imprimé, dans notre condition. Mais comme la longueur de la string ne change pas, nous pouvons vérifier la longueur de la string une fois :#include <cs50.h> #include <stdio.h> #include <string.h> int main(void) { string s = get_string("Entrée : "); printf("Sortie :\n"); for (int i = 0, n = strlen(s); i < n; i++) { printf("%c\n", s[i]); } }- Maintenant, au début de notre boucle, nous initialisons une variable
ietn, et mémorisons la longueur de notre string dansn. Ensuite, nous pouvons vérifier les valeurs à chaque fois, sans avoir à calculer réellement la longueur de la string. - Et nous avons effectivement eu besoin d’un peu plus de mémoire pourn, mais cela nous fait gagner du temps en n’ayant pas à vérifier la longueur de la string à chaque fois.
- Maintenant, au début de notre boucle, nous initialisons une variable
-
Nous pouvons maintenant combiner ce que nous avons vu pour écrire un programme capable de mettre en majuscules des lettres :
#include <cs50.h> #include <stdio.h> #include <string.h> int main(void) { string s = get_string("Avant : "); printf("Après : "); for (int i = 0, n = strlen(s); i < n; i++) { if (s[i] >= 'a' && s[i] <= 'z') { printf("%c", s[i] - 32); } else { printf("%c", s[i]); } } printf("\n"); }- Tout d'abord, nous obtenons une chaîne
s. Ensuite, pour chaque caractère dans la chaîne, s'il est en minuscule (sa valeur est entre celle deaetz), nous le convertissons en majuscule. Sinon, nous l'imprimons simplement. - Nous pouvons convertir une lettre minuscule en son équivalent en majuscule en soustrayant la différence entre leurs valeurs ASCII. (Nous savons que les lettres minuscules ont une valeur ASCII plus élevée que les lettres majuscules, et la différence est commodément la même entre les mêmes lettres, nous pouvons donc soustraire cette différence pour obtenir une lettre majuscule à partir d'une lettre minuscule.)
- Tout d'abord, nous obtenons une chaîne
-
Nous pouvons utiliser les pages de manuel, ou le manuel du programmeur, pour trouver les fonctions de bibliothèque que nous pouvons utiliser pour accomplir la même chose :
#include <cs50.h> #include <ctype.h> #include <stdio.h> #include <string.h> int main(void) { string s = get_string("Avant : "); printf("Après : "); for (int i = 0, n = strlen(s); i < n; i++) { printf("%c", toupper(s[i])); } printf("\n"); }- En recherchant dans les pages du manuel, nous voyons
toupper()est une fonction, entre autres, d'une bibliothèque appeléectype, que nous pouvons utiliser.
- En recherchant dans les pages du manuel, nous voyons
Arguments de ligne de commande
- Nous avons utilisé des programmes tels que
makeetclang, qui prennent des mots supplémentaires après leur nom sur la ligne de commande. Il s’avère que nos propres programmes peuvent également prendre des arguments de ligne de commande. -
Dans
argv.c, nous modifions l’apparence de notre fonctionmain:#include <cs50.h> #include <stdio.h> int main(int argc, string argv[]) { if (argc == 2) { printf("bonjour, %s\n", argv[1]); } else { printf("bonjour, le monde\n"); } }argcetargvsont deux variables que notre fonctionmainreçoit désormais lorsque notre programme est exécuté depuis la ligne de commande.argcest le nombre d’arguments ou le nombre d’arguments, etargvest un tableau de chaînes qui sont les arguments. Et le premier argument,argv [0], est le nom de notre programme (le premier mot tapé, comme./hello). Dans cet exemple, nous vérifions si nous avons deux arguments et, le cas échéant, nous affichons le second.- Par exemple, si nous exécutons
./argv David, nous obtiendronsbonjour, Davidimprimé, puisque nous avons tapéDavidcomme deuxième mot dans notre commande.
-
Il s’avère que nous pouvons indiquer les erreurs dans notre programme en renvoyant une valeur depuis notre fonction
main(comme indiqué par l’intavant notre fonctionmain). Par défaut, notre fonctionmainrenvoie0pour indiquer que rien ne s’est mal passé, mais nous pouvons écrire un programme pour renvoyer une valeur différente :#include <cs50.h> #include <stdio.h> int main(int argc, string argv[]) { if (argc != 2) { printf("argument de ligne de commande manquant\n"); return 1; } printf("bonjour, %s\n", argv[1]); return 0; }- La valeur de retour de
maindans notre programme est appelée code de sortie.
- La valeur de retour de
-
Au fur et à mesure que nous écrivons des programmes plus complexes, des codes d’erreur comme celui-ci peuvent nous aider à déterminer ce qui s’est mal passé, même si ce n’est pas visible ou significatif pour l’utilisateur.
Lisibilité
- Maintenant que nous savons utiliser des chaînes de caractères dans nos programmes, nous pouvons analyser des paragraphes de texte pour évaluer leur niveau de lisibilité, sur la base de facteurs tels que la longueur et la complexité des mots et des phrases.
Cryptage
- Si nous voulons envoyer un message à quelqu'un, nous pouvons vouloir le crypter, ou le brouiller en quelque sorte, pour qu'il soit difficile à lire pour les autres. Le message original, ou l'entrée de notre algorithme, est appelé texte en clair, et le message crypté, ou la sortie, est appelé texte chiffré.
- Un message comme
JE SUIS LA !pourrait être converti en ASCII,72 73 33. Mais n'importe qui pourrait le reconvertir en lettres. - Un algorithme de cryptage nécessite généralement une autre entrée, en plus du texte en clair. Une clé est nécessaire, et parfois ce n'est qu'un nombre qui est gardé secret. Avec la clé, le texte en clair peut être converti, via un algorithme, en texte chiffré, et vice versa.
- Par exemple, si nous voulions envoyer un message comme
JE SUIS LA !, nous pouvons d'abord le convertir en ASCII :72 73 33. Ensuite, nous pouvons le crypter avec une clé de seulement1et un algorithme simple, où nous ajoutons simplement la clé à chaque valeur :74 77 80 87 70 90 80 86. Alors, quelqu'un qui reconvertit cet ASCII en texte verraJF TOV LA !. Pour décrypter ce message, quelqu'un devra connaître la clé. - Nous appliquerons ces concepts dans notre ensemble de problèmes !