Lecon 7
Tablesur des tableurs
- Nous sommes pour la plupart familiers avec les tableurs, des lignes de données, chaque colonne d'une ligne ayant des données distinctes qui se rapportent aux autres d'une certaine façon.
- Une base de données est une application qui peut stocker des données, et nous pouvons penser à Google Sheets comme en étant une de ces applications.
- Par exemple, nous avons créé un Google Form pour demander aux étudiants leur série TV préférée et son genre. Nous examinons les réponses et voyons que la tableur a trois colonnes : « Timestamp », « titre » et « genres » :
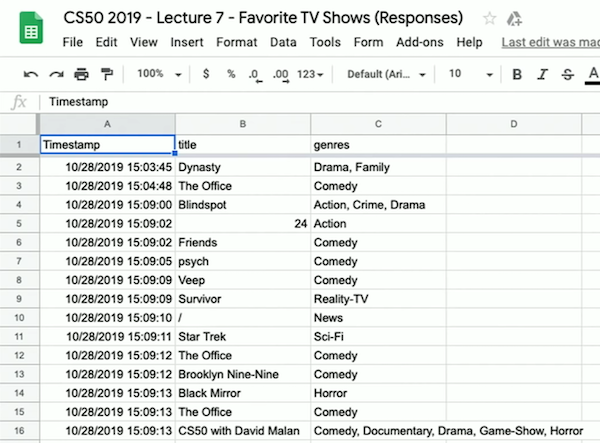
- Nous pouvons télécharger un fichier CSV du tableur avec « Fichier » > « Télécharger », le télécharger dans notre IDE, et voir qu'il s'agit d'un fichier texte avec des valeurs séparées par des virgules qui correspondent aux données du tableur.
-
Nous allons écrire
favorites.py:import csv with open("CS50 2019 - Lecture 7 - Favorite TV Shows (Responses) - Form Responses 1.csv", "r") as file: reader = csv.DictReader(file) for row in reader: print(row["title"])- Nous allons simplement ouvrir le fichier et nous assurer que nous pouvons obtenir le titre de chaque ligne.
-
Maintenant nous pouvons utiliser un dictionnaire pour compter le nombre de fois où nous avons vu chaque titre, avec les clés étant les titres et les valeurs pour chaque clé un entier, en suivant le nombre de fois où nous avons vu ce titre :
import csv counts = {} with open("CS50 2019 - Lecture 7 - Favorite TV Shows (Responses) - Form Responses 1.csv", "r") as file: reader = csv.DictReader(file) for row in reader: title = row["title"] if title in counts: counts[title] += 1 else: counts[title] = 1 for title, count in counts.items(): print(title, count, sep=" | ")- Dans chaque ligne, nous pouvons obtenir le
titleavecrow["title"]. - Ici, si nous avons déjà vu le titre (il est dans
counts), nous pouvons simplement ajouter 1 à la valeur. Sinon, nous devons définir la valeur initiale à 1. - Enfin, nous pouvons imprimer les clés et les valeurs de notre dictionnaire avec un séparateur afin que ce soit un peu plus facile à lire.
- Dans chaque ligne, nous pouvons obtenir le
-
Nous pouvons changer la manière dont nous itérons à
for title, count in sorted(counts.items()), et nous verrons notre dictionnaire trié par les clés, par ordre alphabétique. -
Mais nous pouvons trier par les paires clé-valeur dans le dictionnaire avec :
def f(item): return item[1] for title, count in sorted(counts.items(), key=f, reverse=True):- Nous définissons une fonction,
f, qui renvoie simplement la valeur de l'élémentitemdans le dictionnaire avecitem[1]. La fonctionsorted, à son tour, peut l'utiliser comme clé pour trier les éléments du dictionnaire. Et nous allons également passerreverse=Truepour trier du plus grand au plus petit, au lieu du plus petit au plus grand.
- Nous définissons une fonction,
-
Nous pouvons en fait définir notre fonction sur la même ligne, avec cette syntaxe :
for title, count in sorted(counts.items(), key=lambda item: item[1], reverse=True):- Nous passons une lambda, ou fonction anonyme, comme clé, qui prend en compte
itemet renvoieitem[1].
- Nous passons une lambda, ou fonction anonyme, comme clé, qui prend en compte
-
Enfin, nous pouvons passer tous les titres en minuscules avec
title = row["title"].lower(), afin que nos décomptes puissent être un peu plus précis même si les noms n'ont pas été saisis exactement de la même manière.
SQL
- Nous allons nous tourner vers un nouveau programme dans notre fenêtre de terminal,
sqlite3, un programme en ligne de commande qui nous permet d’utiliser un autre langage, SQL (prononcer comme « séquel »). -
Nous allons exécuter quelques commandes pour créer une nouvelle base de données nommée
favorites.dbet importer notre fichier CSV dans un tableau appelé « favoris » :~/ $ sqlite3 favorites.db SQLite version 3.22.0 2018-01-22 18:45:57 Enter ".help" for usage hints. sqlite> .mode csv sqlite> .import "CS50 2019 - Lecture 7 - Favorite TV Shows (Responses) - Form Responses 1.csv" favorites -
Nous voyons un
favorites.dbdans notre IDE après avoir exécuté ceci, et nous pouvons désormais utiliser SQL pour interagir avec nos données :sqlite> SELECT title FROM favorites; title Dynasty The Office Blindspot 24 Friends psych Veep Survivor ... -
Nous pouvons même trier nos résultats :
sqlite> SELECT title FROM favorites ORDER BY title; title / 24 9009 Adventure Time Airplane Repo Always Sunny Ancient Aliens ... -
Et obtenir un compte du nombre de fois où chaque titre apparaît :
sqlite> SELECT title, COUNT(title) FROM favorites GROUP BY title; title | COUNT(title) / | 1 24 | 1 9009 | 1 Adventure Time | 1 Airplane Repo | 1 Always Sunny | 1 Ancient Aliens | 1 ... -
Nous pouvons même définir le compte de chaque titre sur une nouvelle variable,
n, et ordonner nos résultats par celle-ci, en ordre décroissant. Puis nous pouvons voir les 10 premiers résultats avecLIMIT 10:sqlite> SELECT title, COUNT(title) AS n FROM favorites GROUP BY title ORDER BY n DESC LIMIT 10; title | n The Office | 30 Friends | 20 Game of Thrones | 20 Breaking Bad | 14 Black Mirror | 9 Rick and Morty | 9 Brooklyn Nine-Nine | 5 Game of thrones | 5 No | 5 Prison Break | 5 -
SQL est un langage qui nous permet de travailler avec une base de données relationnelle, une application nous permet de stocker des données et de travailler dessus plus rapidement qu'avec un fichier CSV.
-
Avec
.schema, nous pouvons voir comment le format de la table pour nos données est créé :sqlite> .schema CREATE TABLE favorites( "Timestamp" TEXT, "title" TEXT, "genres" TEXT ); -
Il s'avère que, lorsque nous travaillons avec des données, nous n'avons besoin que de quatre opérations :
CREATEREADUPDATEDELETE
- En SQL, les commandes pour effectuer chacune de ces opérations sont :
INSERTSELECTUPDATEDELETE
- Tout d’abord, nous devrons insérer une table à l'aide de la commande
CREATE TABLE table (type de colonne, ...);. - SQL, a également ses propres types de données pour optimiser la quantité d’espace utilisé pour le stockage des données :
BLOB, pour « binary large object », données binaires brutes pouvant représenter des fichiersINTEGERsmallintintegerbigint
NUMERICbooleandatedatetimenumeric(scale,precision), qui résout l'imprécision à virgule flottante en utilisant autant de bits que nécessaire, pour chaque chiffre avant et après la virguletimetimestamp
REALreal, pour les valeurs à virgule flottantedouble precision, avec plus de bits
TEXTchar(n), pour un nombre exact de caractèresvarchar(n), pour un nombre variable de caractères, jusqu'à une certaine limitetext
- SQLite est une application de base de données qui prend en charge SQL, et de nombreuses entreprises proposent des applications serveur qui prennent en charge SQL, notamment Oracle Database, MySQL, PostgreSQL, MariaDB et Microsoft Access.
- Après avoir inséré des valeurs, nous pouvons également utiliser des fonctions pour effectuer des calculs :
AVGCOUNTDISTINCT, pour obtenir des valeurs distinctes sans doublonsMAXMIN- …
- Il existe également d'autres opérations que nous pouvons combiner selon les besoins :
WHERE, correspondant à une condition stricteLIKE, correspondant à des sous-chaînes pour le texteLIMITGROUP BYORDER BYJOIN, combinant les données de plusieurs tables
- Nous pouvons mettre à jour les données avec
UPDATE table SET column=value WHERE condition ;, qui peut inclure 0, 1 ou plusieurs lignes selon notre condition. Par exemple, nous pourrions direUPDATE favorites SET title = "The Office" WHERE title LIKE "%office", et cela définira toutes les lignes avec le titre contenant « office » comme étant « The Office » afin que nous puissions les rendre cohérentes. - Et nous pouvons supprimer les lignes correspondantes avec
DELETE FROM table WHERE condition ;, comme dansDELETE FROM favorites WHERE title = "Friends";. - Nous pouvons même supprimer complètement une table entière avec une autre commande,
DROP.
IMDb
- IMDb, ou « Internet Movie Database », dispose d'ensembles de données disponibles en téléchargement en tant que fichiers TSV ou valeurs séparées par des tabulations.
- Par exemple, nous pouvons télécharger
title.basics.tsv.gz, qui contiendra des données de base sur des titres :tconst, un identifiant unique pour chaque titre, commett4786824titleType, le type de titre, commetvSeriesprimaryTitle, le titre principal utilisé, commeThe CrownstartYear, l'année de sortie du titre, comme2016genres, une liste de genres séparés par des virgules, commeDrama,History
- Nous jetons un œil à
title.basics.tsvaprès l'avoir décompressé, et nous voyons que les premières rangées sont bien les en-têtes que nous attendions et que chaque rangée a des valeurs séparées par des tabulations. Mais le fichier contient plus de 6 millions de rangées, donc même la recherche d'une valeur prend un moment. - Nous allons télécharger le fichier dans notre EDI avec
wget, puisgunzippour le décompresser. Mais notre EDI n'a pas assez d'espace, nous allons donc utiliser le terminal de notre Mac à la place. -
Nous allons écrire
import.pypour lire le fichier :import csv # Ouvrir le fichier TSV en lecture with open("title.basics.tsv", "r") as titres : # Le fichier est un fichier TSV, nous pouvons donc utiliser le lecteur CSV et changer le séparateur en une tabulation. lecteur = csv.DictReader(titres, delimiter="\t") # Ouvrir un nouveau fichier CSV en écriture with open("shows0.csv", "w") as spectacles : # Créer l'auteur auteur = csv.writer(spectacles) # Écrire l'en-tête des colonnes que nous voulons auteur.writerow(["tconst", "primaryTitle", "startYear", "genres"]) # Itérer sur le fichier TSV for ligne in lecteur : # Si série télévisée non-adultes if ligne["titleType"] == "tvSeries" and ligne["isAdult"] == "0": # Écrire la ligne auteur.writerow([ligne["tconst"], ligne["primaryTitle"], ligne["startYear"], ligne["genres"]]) -
Dorénavant, nous pouvons ouvrir
shows0.csvet voir un ensemble plus réduit de données. Mais il s'avère que, pour certaines rangées,startYeara une valeur égale à\N, et c'est une valeur spéciale d'IMDb lorsqu'ils veulent représenter des valeurs manquantes. Nous pouvons donc filtrer ces valeurs et convertir l'année de début en un entier pour filtrer les séries après 1970 :... # Si l'année n'est pas manquante (nous devons également échapper la barre oblique inverse) if ligne["startYear"] != "\\N": # Si depuis 1970 if int(ligne["startYear"]) >= 1970 : # Écrire la ligne auteur.writerow([ligne["tconst"], ligne["primaryTitle"], ligne["startYear"], ligne["genres"]]) -
Nous pouvons écrire un programme pour rechercher un titre donné :
import csv # Inviter l'utilisateur pour le titre title = input("Titre : ") # Ouvrir le fichier CSV with open("shows2.csv", "r") as input: # Créer DictReader reader = csv.DictReader(input) # Itérer sur le fichier CSV for row in reader: # Rechercher le titre if title.lower() == row["primaryTitle"].lower(): print(row["primaryTitle"], row["startYear"], row["genres"], sep=" | ")- Nous pouvons exécuter ce programme et voir nos résultats, mais nous pouvons voir comment SQL peut faire un meilleur travail.
-
En Python, nous pouvons nous connecter à une base de données SQL et y lire notre fichier une fois, afin de pouvoir effectuer de nombreuses requêtes sans écrire de nouveaux programmes et sans avoir à lire le fichier entier à chaque fois.
-
Faisons cela plus facilement avec la bibliothèque CS50 :
import cs50 import csv # Créer une base de données en ouvrant puis fermant d'abord un fichier vide open(f"shows3.db", "w").close() db = cs50.SQL("sqlite:///shows3.db") # Créer une table intitulée "shows", et spécifier les colonnes que nous voulons, # qui seront tous du texte à l'exception de "startYear" db.execute("CREATE TABLE shows (tconst TEXT, primaryTitle TEXT, startYear NUMERIC, genres TEXT)") # Ouvrir le fichier TSV # https://datasets.imdbws.com/title.basics.tsv.gz with open("title.basics.tsv", "r") as titles: # Créer DictReader reader = csv.DictReader(titles, delimiter="\t") # Itérer sur le fichier TSV for row in reader: # S'il s'agit d'une émission de télévision non-adultes if row["titleType"] == "tvSeries" and row["isAdult"] == "0": # Si l'année n'est pas manquante if row["startYear"] != "\\N": # Si depuis 1970 startYear = int(row["startYear"]) if startYear >= 1970: # Insérer l'émission en substituant les valeurs dans chaque espace réservé ? db.execute("INSERT INTO shows (tconst, primaryTitle, startYear, genres) VALUES(?, ?, ?, ?)", row["tconst"], row["primaryTitle"], startYear, genres) -
Maintenant, nous pouvons exécuter
sqlite3 shows3.dbet exécuter des commandes comme avant, commeSELECT * FROM shows LIMIT 10 ;. - Avec
SELECT COUNT(*) FROM shows ;nous pouvons voir qu'il y a plus de 150 000 émissions dans notre table, et avecSELECT COUNT(*) FROM shows WHERE startYear = 2019 ;, nous voyons qu'il y en avait plus de 6 000 cette année.
Tableaux multiples
-
Mais chacune des lignes n'aura qu'une colonne pour les genres et les valeurs sont plusieurs genres rassemblés. Nous pouvons donc revenir à notre programme d'importation et ajouter une autre table :
import cs50 import csv # Créer une base de données open(f"shows4.db", "w").close() db = cs50.SQL("sqlite:///shows4.db") # Créer des tableaux db.execute("CREATE TABLE shows (id INT, title TEXT, year NUMERIC, PRIMARY KEY(id))") # La table `genres` aura une colonne appelée `show_id` qui fait référence à la table `shows` ci-dessus db.execute("CREATE TABLE genres (show_id INT, genre TEXT, FOREIGN KEY(show_id) REFERENCES shows(id))") # Ouvrir un fichier TSV # https://datasets.imdbws.com/title.basics.tsv.gz with open("title.basics.tsv", "r") as titles: # Créer un DictReader reader = csv.DictReader(titles, delimiter="\t") # Parcourir le fichier TSV for row in reader: # S'il s'agit d'une émission de télévision non destinée aux adultes if row["titleType"] == "tvSeries" and row["isAdult"] == "0": # Si l'année n'est pas manquante if row["startYear"] != "\\N": # Si depuis 1970 startYear = int(row["startYear"]) if startYear >= 1970: # Supprimer le préfixe de tconst id = int(row["tconst"][2:]) # Insérer l'émission db.execute("INSERT INTO shows (id, title, year) VALUES(?, ?, ?)", id, row["primaryTitle"], startYear) # Insérer les genres if row["genres"] != "\\N": for genre in row["genres"].split(","): db.execute("INSERT INTO genres (show_id, genre) VALUES(?, ?)", id, genre)- Ainsi, notre table
showsn'a plus de colonnegenres, mais nous avons maintenant une tablegenresavec chaque ligne représentant une émission et un genre associé. Désormais, une émission particulière peut avoir plusieurs genres que nous pouvons rechercher, et nous pouvons obtenir d'autres données sur l'émission à partir de la tableshowsgrâce à son ID.
- Ainsi, notre table
-
En fait, nous pouvons combiner les deux tables avec
SELECT * FROM shows WHERE id IN (SELECT show_id FROM genres WHERE genre = "Comedy") AND year = 2019;. Nous filtrons notre tableshowspar ID lorsque l'ID dans la tablegenresa une valeur de “Comedy” pour la colonnegenreet une valeur de 2019 pour la colonneyear. - Nos tables ressemblent à ceci :
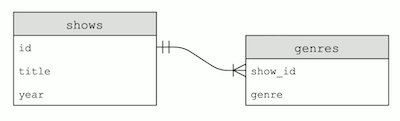
- Étant donné que l'ID dans la table
genreprovient de la tableshows, nous l'appelonsshow_id. Et la flèche indique qu'un même ID d'émission peut avoir de nombreuses lignes correspondantes dans la tablegenres.
- Étant donné que l'ID dans la table
- Nous voyons que certains jeux de données d'IMDb, comme
title.principals.tsv, ne comportent que des ID pour certaines colonnes que nous devrons rechercher dans d'autres tables. - En lisant les descriptions de chaque table, nous pouvons voir que toutes les données peuvent être utilisées pour créer ces tables :
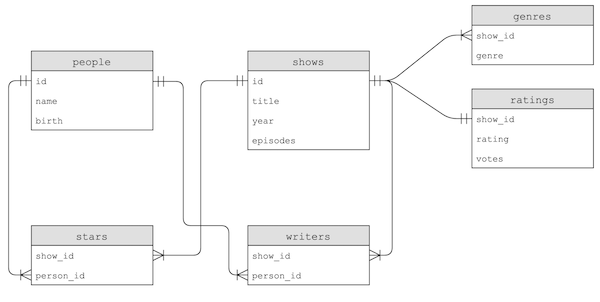
- Notez que, par exemple, le nom d'une personne peut également être copié dans les tables
starsouwriters, mais seul leperson_idest utilisé pour créer un lien vers les données de la tablepeople. De cette façon, nous n'avons besoin de mettre à jour le nom qu'à un seul endroit si nous devons effectuer une modification.
- Notez que, par exemple, le nom d'une personne peut également être copié dans les tables
- Nous allons ouvrir une base de données,
shows.db, avec ces tables pour voir d'autres exemples. - Nous allons télécharger un programme appelé DB Browser for SQLite, qui disposera d'une interface utilisateur graphique pour parcourir nos tables et nos données. Nous pouvons également utiliser l'onglet “Execute SQL” pour exécuter directement du SQL dans le programme.
- Nous pouvons exécuter
SELECT * FROM shows JOIN genres ON show.id = genres.show_id;pour joindre deux tables en faisant correspondre les ID dans les colonnes que nous spécifions. Nous obtiendrons alors une table plus large, avec des colonnes de chacune de ces deux tables. - Nous pouvons prendre l'ID d'une personne et la retrouver dans les émissions avec
SELECT * FROM stars WHERE person_id = 1122;, mais nous pouvons faire une requête dans notre requête avecSELECT show_id FROM stars WHERE person_id = (SELECT id FROM people WHERE name = "Ellen DeGeneres");. - Cela nous renvoie le
show_id, donc pour obtenir les données de l'émission, nous pouvons exécuter :SELECT * FROM shows WHERE id IN (...);avec...étant la requête ci-dessus. -
Nous pouvons obtenir les mêmes résultats avec :
SELECT title FROM people JOIN stars ON people.id = stars.person_id JOIN shows ON stars.show_id = shows.id WHERE name = "Ellen DeGeneres"- Nous joignons la table
peopleavec la tablestars, puis avec la tableshowsen spécifiant les colonnes qui doivent correspondre entre les tables, puis en sélectionnant uniquement letitreavec un filtre sur le nom. - Mais maintenant, nous pouvons également sélectionner d'autres champs dans nos tables combinées.
- Nous joignons la table
-
Il s'avère que nous pouvons spécifier que des colonnes de nos tables soient des types spéciaux, tels que :
PRIMARY KEY, utilisé comme identifiant principal pour une ligneFOREIGN KEY, qui pointe vers une ligne d'une autre tableUNIQUE, ce qui signifie qu'il doit être unique dans cette tableINDEX, qui demande à notre base de données de créer un index pour interroger plus rapidement en fonction de cette colonne. Un index est une structure de données telle qu'un arbre qui nous aide à rechercher des valeurs.
- Nous pouvons créer un index avec
CREATE INDEX person_index ON stars (person_id);. Ensuite, la colonneperson_idaura un index appeléperson_index. Avec les bons index, notre requête de jonction est plusieurs centaines de fois plus rapide.
Problèmes
- Un problème avec les bases de données est la condition de course, dans laquelle le moment de deux actions ou évènements provoque un comportement inattendu.
- Par exemple, prenons deux colocataires et un frigo partagé dans leur dortoir. Le premier colocataire rentre chez lui et voit qu'il n'y a plus de lait dans le frigo. Il part donc au magasin pour acheter du lait et, alors qu'il est au magasin, le deuxième colocataire rentre chez lui, voit qu'il n'y a plus de lait et part dans un autre magasin pour en acheter. Plus tard, il y aura deux briques de lait dans le frigo. En laissant un mot, on peut résoudre ce problème. On peut même verrouiller le frigo pour que notre colocataire ne puisse pas vérifier s'il y a du lait jusqu'à notre retour.
-
Cela peut se produire dans notre base de données si nous avons quelque chose comme ceci :
rows = db.execute("SELECT likes FROM posts WHERE id=?", id); likes = rows[0]["likes"] db.execute("UPDATE posts SET likes = ?", likes + 1);- Premièrement, nous obtenons le nombre de likes sur un post avec un ID donné. Ensuite, nous définissons le nombre de likes comme étant ce nombre plus un.
- Mais maintenant, si nous avons deux serveurs web différents essayant tous les deux d'ajouter un like, ils pourraient tous les deux le définir comme étant la même valeur au lieu d'en ajouter réellement un à chaque fois. Par exemple, s'il y a 2 likes, les deux serveurs vérifieront le nombre de likes, verront qu'il y en a 2 et définira la valeur à 3. L'un des likes sera alors perdu.
-
Pour résoudre ce problème, nous pouvons utiliser des transactions, dans lesquelles un ensemble d'actions est garanti de se produire ensemble.
- Un autre problème en SQL est appelé attaque par injection SQL, dans laquelle un adversaire peut exécuter ses propres commandes sur notre base de données.
- Par exemple, quelqu'un pourrait essayer de saisir
malan@harvard.edu'--comme adresse e-mail. Si nous avons une requête SQL qui est une chaîne formatée (sans échappement ou substitution de caractères dangereux à partir de l'entrée), commef"SELECT * FROM users WHERE username = '{username}' AND password = '{password}'", alors la requête finira par êtref"SELECT * FROM users WHERE username = 'malan@harvard.edu'--' AND password = '{password}'", ce qui sélectionnera en fait la ligne oùusername = 'malan@harvard.edu'et transformera le reste de la ligne en commentaire. Pour éviter cela, nous devrions utiliser des espaces réservés?pour que notre bibliothèque SQL échappe automatiquement les entrées de l'utilisateur.